Kaplan-Meier-Kurve
Andreas Mock
Kaum eine klinische Studie kommt ohne Überlebenszeitanalysen aus. Deshalb sollte die sachkundige Durchführung und Interpretation dieser zum Rüstzeug jedes Mediziners gehören.
survival: Paket für statistischen Berechnungensurvminer: Paket für Visualisierung der Kaplan-Meier-Kurven auf Basis von ggplot2broom: Paket für ErgebnisstabellenWir werden wieder mit dem hnscc-Datensatz arbeiten.
Für eine vergleichende Überlebenszeitanalysen benötigen wir drei Informationen:
## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## 0.0 218.8 443.0 789.0 999.2 6416.0 1##
## DECEASED LIVING
## 116 163## [1] "age" "alcohol" "gender" "neoplasm_site"
## [5] "grade" "pack_years" "tabacco_group" "tumor_stage"Diese Datentransformation entspricht der Übung 1 des heutigen Tages. Hierbei werden wir für die weitere Analyse ein eigenes Objekt hnscc_survival erstellen.
Für Überlebenszeitanalysen in R gilt es von so genannten survival Objekten gebrauch zu machen. Diese sind Teil des survival Pakets.
Die Syntax ist straightforward:
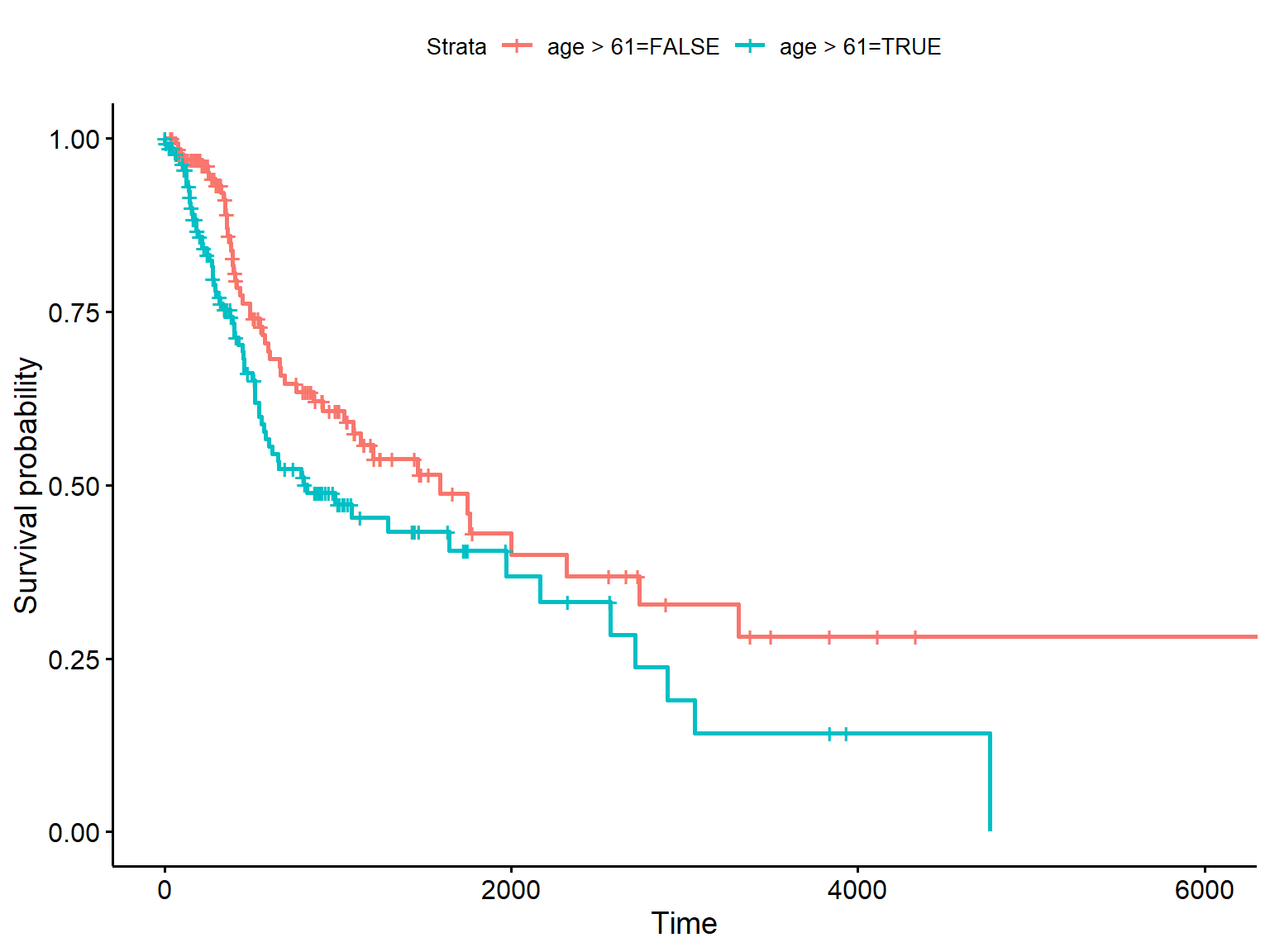
## [1] 461 415 1134 276 248+ 190+Der Klassiker der Visualisierung von Überlebenszeitanalysen ist die so genannte Kaplan-Meier-Kurve.
Wichtig: Überlebenszeitanalysen können auch für kontinuierliche Einflussfaktoren durchgeführt werden. Hier macht natürlich eine Visualisierung mittels Kaplan-Meier-Kurve keinen Sinn.
Für diese müssen wir noch die Gruppenzugehörigkeit angeben, und das Objekt für den Plot mit survfit herstellen:
## [1] 61## Call: survfit(formula = Surv(OS, Censor) ~ age > 61, data = hnscc_survival)
##
## 1 observation deleted due to missingness
## n events median 0.95LCL 0.95UCL
## age > 61=FALSE 139 50 1591 1037 3314
## age > 61=TRUE 139 66 822 572 2166library(broom)
# Beispiel 1: Alter dichotomisiert nach > Median (= 61 Jahre)
tidy(coxph(Surv(OS, Censor)~age>61, data=hnscc_survival),
exponentiate = TRUE)## # A tibble: 1 x 5
## term estimate std.error statistic p.value
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 age > 61TRUE 1.54 0.189 2.27 0.0229# Beispiel 2: Alter als kontiniuerliche Variable
tidy(coxph(Surv(OS, Censor)~age, data=hnscc_survival),
exponentiate = TRUE)## # A tibble: 1 x 5
## term estimate std.error statistic p.value
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 age 1.02 0.00827 2.69 0.00718Estimate = HR
##
## Current reformed smoker for < or = 15 years
## 81
## Current reformed smoker for > 15 years
## 49
## Current smoker
## 90
## Lifelong Non-smoker
## 52## # A tibble: 3 x 5
## term estimate std.error statistic p.value
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 tabacco_groupCurrent reformed smoker for~ 0.572 0.290 -1.93 0.0542
## 2 tabacco_groupCurrent smoker 1.14 0.234 0.551 0.582
## 3 tabacco_groupLifelong Non-smoker 0.482 0.307 -2.38 0.0173In der multivariaten Überlebenszeitanalyse kombinieren wir die Einflussfaktoren zusammen, die univariat signifikant waren. Wir wollen herausfinden, ob diese unabhängige Einflussfaktoren sind.
# Beispielmodel: Alter und Tabacco group
tidy(coxph(Surv(OS, Censor)~age + tabacco_group, data=hnscc_survival),
exponentiate = TRUE)## # A tibble: 4 x 5
## term estimate std.error statistic p.value
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 age 1.02 0.00931 2.58 0.00986
## 2 tabacco_groupCurrent reformed smoker for~ 0.520 0.292 -2.23 0.0255
## 3 tabacco_groupCurrent smoker 1.22 0.235 0.838 0.402
## 4 tabacco_groupLifelong Non-smoker 0.553 0.309 -1.92 0.0552